Data Ops Costs
(simulate operations costs based on input parameters)
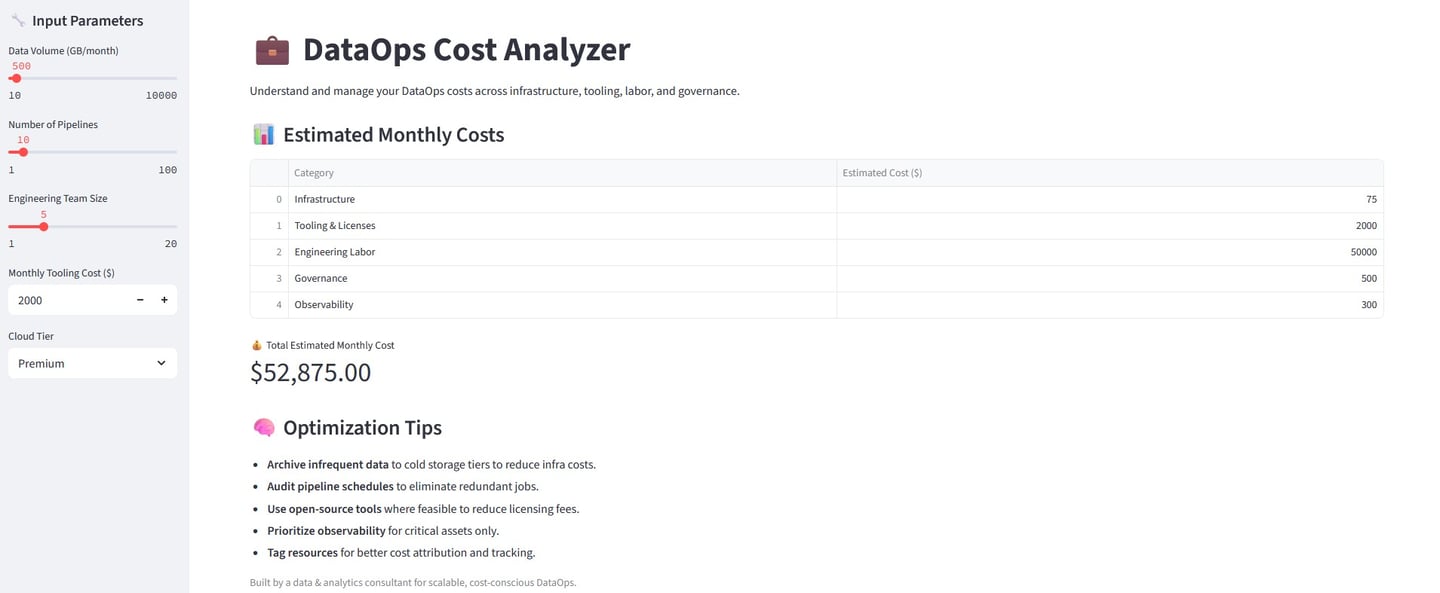

Understanding and Managing DataOps Costs
DataOps, short for Data Operations, is the discipline of orchestrating people, processes, and technology to deliver reliable, scalable, and timely data pipelines. While it promises agility and governance, it also introduces a complex cost structure that spans infrastructure, tooling, labor, and compliance. Understanding these costs is key to optimizing ROI and aligning data strategy with business outcomes.
Key Cost Categories in DataOps
Infrastructure costs refer to the cloud compute, storage, and networking resources required to run data pipelines and platforms. These costs are typically driven by the volume of data processed, the frequency of pipeline execution, and the cloud service tier selected (e.g., standard vs enterprise).
Tooling and license costs encompass the expenses associated with ETL platforms, orchestration tools, monitoring systems, and version control software. These costs vary based on subscription models, usage-based pricing, and the number of connectors or integrations used.
Engineering labor costs represent the salaries and overhead for data engineers, DevOps professionals, and platform architects. The size and skill level of the team, as well as the velocity of development and maintenance, significantly influence this category.
Governance and compliance costs arise from the need to maintain data lineage, enforce access controls, conduct audits, and ensure privacy compliance. These costs scale with the complexity of the regulatory environment and the sophistication of the governance tooling.
Observability and quality assurance costs include the tools and processes used to monitor pipeline health, validate data quality, and trigger alerts. The granularity of checks and whether monitoring is real-time or batch-based can impact the overall spend.
Tools That Influence DataOps Costs
Pipeline orchestration tools such as Apache Airflow, Prefect, and Dagster help manage task dependencies and scheduling. Costs here depend on whether the tool is self-hosted or SaaS-based, the complexity of directed acyclic graphs (DAGs), and the degree of parallelism required. To reduce compute costs, it's wise to modularize DAGs and avoid over-triggering jobs.
ETL and ELT platforms like dbt, Fivetran, Talend, and Apache NiFi facilitate data extraction, transformation, and loading. Their pricing models often hinge on data volume, transformation complexity, and the number of connectors used. A cost-saving strategy is to push down transformations to the data warehouse, especially when using tools like dbt with Snowflake.
Data storage and compute platforms such as Snowflake, BigQuery, Redshift, and cloud storage services like S3 or Azure Blob Storage are foundational to DataOps. Costs are influenced by query frequency, storage tier selection, and compute scaling policies. Archiving infrequently accessed data to cold storage tiers can significantly reduce expenses.
Monitoring and observability tools including Monte Carlo, Great Expectations, Datadog, and Prometheus help ensure pipeline reliability and data integrity. The cost impact depends on how granular the checks are, how long data is retained, and how many alerts are generated. Focusing observability efforts on critical data assets can prevent unnecessary overhead.
Version control and CI/CD tools such as GitHub, GitLab, Jenkins, and CircleCI support collaborative development and automated deployment. Costs here are tied to pipeline frequency, runner usage, and artifact storage. Optimizing CI/CD pipelines with caching and parallel jobs can reduce runtime and associated costs.
Processes to Understand and Control DataOps Spend
Cost attribution is essential for visibility. By tagging resources according to project, team, or pipeline, organizations can use cloud-native tools like AWS Cost Explorer or GCP Billing Reports to track and allocate expenses accurately.
Pipeline auditing involves regularly reviewing pipeline schedules, dependencies, and execution patterns. This helps identify redundant or overly frequent jobs that may be consuming unnecessary resources.
Data tiering strategies enable organizations to classify data based on usage frequency and business criticality. Applying lifecycle policies to move data across storage tiers—from hot to cold—can optimize storage costs without sacrificing accessibility.
Tool rationalization is a strategic exercise in reducing redundancy. By consolidating overlapping tools and evaluating open-source alternatives for non-critical workloads, organizations can streamline their tech stack and reduce licensing fees.
Performance benchmarking provides the metrics needed to optimize both code and infrastructure. Tracking pipeline execution time, resource usage, and failure rates allows teams to identify bottlenecks and improve efficiency.
AI-First Consulting Automation to Empower your Business with Data-Driven Transformation.
© 2025. All rights reserved.
Purpose. Presence. Service